

Hoewel Mark Rutte lijkt te hebben gemorst dat AI Heroes de hipste start-up van Amsterdam is, heeft hij dit niet echt gezegd tijdens zijn toespraak. Deze video is gemaakt met behulp van kunstmatige intelligentie (AI). Het is gemaakt met behulp van een combinatie van echte beelden van onze minister-president tijdens zijn toespraak en een audiofragment van de gewenste boodschap die wij hem willen laten zeggen. Omdat Mark Rutte deze woorden niet echt zei, gebruiken we AI om zijn lippen te bewegen zodat het audiofragment overeenkomt met de videobeelden. Laten we eens dieper duiken in de technieken achter het maken van deze zogenaamde face-reenactments (ook wel 'deepfakes' genoemd).
De intuïtie van de techniek
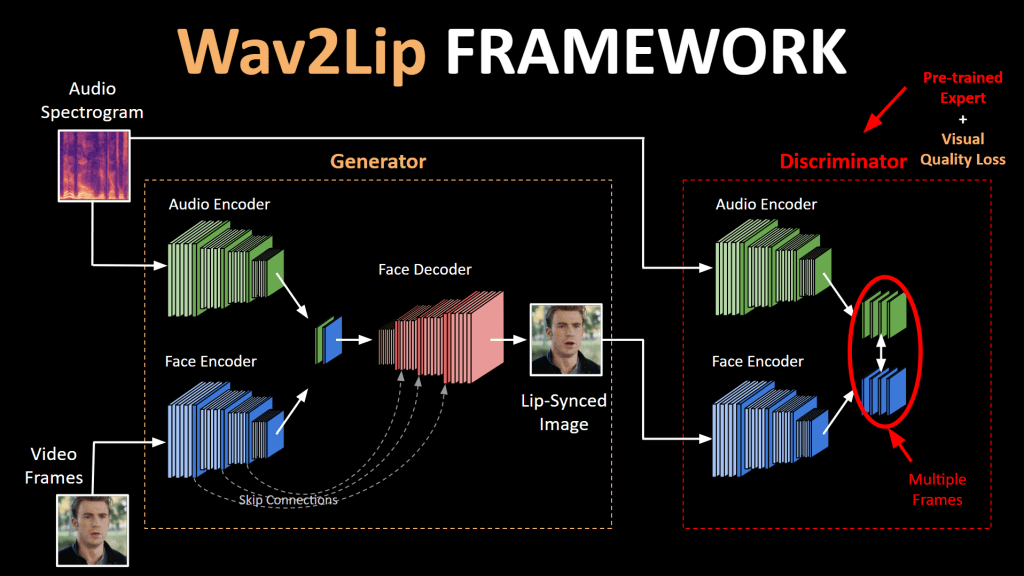
Het synchroniseren van de lippen van de spreker met het audiofragment gebeurt eigenlijk met behulp van vrij intuïtieve technieken. De video in deze blog is gemaakt met behulp van een model genaamd Wav2Lip, en de makers beschrijven hun model als "Het genereren van nauwkeurige lipsynchronisatie door te leren van een goed getrainde lipsynchronisatie-expert"[1]. Dit beschrijft in essentie hoe een General Adversarial Neural Network (GAN) werkt, wat het klassieke model is dat wordt gebruikt om deze video's met face-reenactment te maken.
GAN's werden oorspronkelijk ontwikkeld voor het genereren van afbeeldingen, maar werden aangepast om video's te kunnen genereren. Het belangrijke verschil tussen het genereren van afbeeldingen en video's is dat voor het genereren van video's de temporele consistentie van belang is. Dit betekent dat de frames die individueel worden gegenereerd, in lijn moeten zijn met andere frames om op een 'beweging' in de tijd te lijken.
Technologie
Een GAN gebruikt twee neurale netwerken die met elkaar communiceren om een betere versie van zichzelf te worden. Net als twee schakers die beter worden als ze tegen elkaar spelen. Dit traint de GAN om levensechte lipsyncs te genereren.
Het eerste neurale netwerk (de 'generator') genereert een beeld van de gezichtshouding in de originele video, samengevoegd met de onderste helft van het gegenereerde gezicht (de gesynchroniseerde lippen). Het corresponderende audiosegment wordt ook als input gegeven aan de generator en het netwerk genereert de gezichtsuitsnede van de input, maar met het mondgebied gemorphed.
Het tweede netwerk is de zogenaamde 'discriminator'. De discriminator wordt getraind om 'sync' tussen audio en video te discrimineren door willekeurig een audiofragment te samplen dat ofwel in-sync is met de video of van een andere tijdstap (out-of-sync). Dit is wat we in het begin de 'lipsync-expert' hebben genoemd en wordt gebruikt om te beoordelen of de generator levensechte lipsyncs genereert of niet. Het model gebruikt dit oordeel van de discriminator om elke iteratie te verbeteren en nauwkeurigere lipsyncs te genereren! Zodra onze lipsync-expert de echte video en de gegenereerde video niet meer van elkaar kan onderscheiden, is het model goed getraind en kunnen we het gebruiken om realistisch ogende face-reenactments te maken.
Aanpassingen
De technologie van face-reenactments heeft ons in staat gesteld om kunstmatig video's te maken die extreem levensecht zijn. Daarom zijn sommige mensen bang dat dit kan bijdragen aan bijvoorbeeld de verspreiding van nepnieuws en wraakvideo's. Dit kan waar zijn, maar er zijn ook veel manieren waarop we deepfakes voor een goed doel kunnen gebruiken. Hoewel dit waar kan zijn, zijn er ook veel manieren waarop we deepfakes voor een goed doel kunnen gebruiken. Vertalingen van toespraken kunnen bijvoorbeeld gesynchroniseerd worden om de lippen van de spreker te laten overeenkomen met de taal waarnaar het vertaald is. Ook nagesynchroniseerde tv-programma's kunnen lipsynchroniseerd worden zodat ze overeenkomen met de nagesynchroniseerde taal. Daarnaast kunnen we deze technieken gebruiken om het maken van animatiefilms een stuk efficiënter en nauwkeuriger te maken door de gezichtsbewegingen van een personage te genereren.
Naast deze praktische toepassingen is de techniek om levensechte face-reenactments te maken niet zo ontoegankelijk als het misschien lijkt. Waar Martin Scorsese miljoenen dollars uitgaf om Robert De Niro digitaal te de-agen met behulp van traditionele CGI voor de film The Irishmen, probeerde een YouTuber hetzelfde met behulp van gratis toegankelijke AI-software. Dit kostte hem slechts zeven dagen en het ziet er een stuk beter uit! Lees hier meer over.
De technieken om deze deepfakes te genereren zien er veelbelovend uit en lijken soms al bijna perfect te werken. Er valt echter nog veel te leren op het gebied van ethiek en hoe deze technieken kunnen worden toegepast op manieren waar ze echt nuttig kunnen zijn. Of dat nu is om taalbarrières te doorbreken, werkprocessen te optimaliseren of domme video's te maken, de toekomst is hier en AI Heroes maakt er deel van uit!
Bronnen
- Prajwal, K. R., et al. "A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild." Proceedings of the 28th ACM International Conference on Multimedia, ACM, 2020, pp. 484-92. DOI.org (Crossref), doi:10.1145/3394171.3413532.
- Matt Miller, "Some Deepfaker on YouTube Spent Seven Days Fixing the Shitty De-Aging in The Irishman", Jan 2020.

