


Chinese automatische vertaalsystemen: ons ver vooruit of gewoon een slechte vertaling?
Een fundamenteel onderdeel van het mens-zijn is het vermogen om met elkaar te communiceren. Met ruwweg 6500 talen die wereldwijd worden gesproken en onze wereld die steeds meer verbonden raakt door voortschrijdende technologieën en snelle globalisering, is automatische vertaling een essentieel onderdeel van ons bestaan. Snelle en nauwkeurige taalvertalingen dienen grotendeels als onze brug tussen mensen uit andere landen en etnische gemeenschappen.
Om deze snelle en nauwkeurige vertalingen daadwerkelijk te kunnen leveren, hebben verschillende bedrijven de afgelopen jaren veel geïnvesteerd in automatische vertalingen. Er is ook veel vooruitgang geboekt op het gebied van kunstmatige intelligentie. Met name op het gebied van deep learning: een deelgebied binnen AI dat zich bezighoudt met algoritmen die zijn geïnspireerd op de structuur en functie van de hersenen, genaamd 'kunstmatige neurale netwerken'. Samen met deze investeringen heeft AI een aanzienlijke verbetering van de kwaliteit van automatische vertalingen mogelijk gemaakt. Google verklaarde een paar jaar geleden dat "de overstap naar deep learning een toename van 60% in de nauwkeurigheid van vertalingen opleverde"[1]. Maar hoe werkt automatische vertaling (in het bijzonder Google Translate) en waardoor presteert het zo goed?
Google Vertalingen
Voorheen gebruikte Google een statistische machine vertaalmethode (SMT), waarbij de ingevoerde tekst eerst naar het Engels moest worden omgezet voordat deze naar de gewenste taal kon worden vertaald. Dit kost extra tijd en omdat SMT voorspellende algoritmes gebruikte om de tekst te vertalen, was er ook meer ruimte voor slechte grammaticale vertalingen.
Tegenwoordig gebruikt het Google Neural Machine Translation systeem (GNMT) een Long Short-Term Memory Neural Network (LSTM) voor hun automatische vertalingen. Het GNMT werkt zo efficiënt omdat het zijn parameters deelt tussen taalparen om zichzelf te trainen. Wanneer iemand een zin vertaalt van het Japans naar het Engels en van het Spaans naar het Engels, leert het model deze vertalingen en kan het deze kennis aanpassen wanneer iemand een contextueel vergelijkbare zin wil vertalen van het Japans naar het Spaans (wat een talencombinatie kan zijn die het model nog nooit eerder heeft gezien in de context van de gegeven zin!) Dit wordt "zero-shot" vertaling genoemd.
GNMT vertaalt ook hele zinnen in één keer, in plaats van woord voor woord of zelfs karakter voor karakter. Het maakt gebruik van een bredere context om de meest relevante vertaling te achterhalen, die vervolgens wordt herschikt en aangepast om meer op menselijke gesproken taal te lijken met correct gebruikte grammatica.
LSTMS
Waarom werken deze zogenaamde LSTM's zo goed? In een traditioneel ('volledig verbonden') neuraal netwerkmodel stroomt de informatie slechts in één richting: van input naar output en is het alleen in staat om afzonderlijke gegevenspunten per keer te verwerken. Het 'vergeet' de informatie van de gegevens die het al heeft verwerkt, terwijl onze biologische hersenen in staat zijn om dergelijke informatie in ons lange- of kortetermijngeheugen te bewaren.
Een LSTM is een type Recurrent Neural Network (RNN). In tegenstelling tot traditionele neurale netwerken nemen RNN's reeksen gegevens als invoer en sturen ze ook reeksen gegevens terug als uitvoer. Voor machinevertaling is deze gegevensreeks een stuk tekst, maar dit kan ook een audiofragment of een reeks aandelenkoersen zijn. Het belangrijkste is dat de gegevens sequentieel zijn. Een RNN is 'recurrent', omdat elke laag in het model een lus heeft die informatie gebruikt die eerder in het model is gevonden. Deze lus maakt het mogelijk om relevante outputs van eerdere tijdstappen te gebruiken en toe te passen op het model dat in de huidige tijdstap leert. Wat de LSTM onderscheidt van een RNN is dat een LSTM in staat is om 'relevante' en 'irrelevante' informatie te filteren in elk van deze lussen. Deze herhaling dient als het 'geheugen' van het model.
Laten we globaal bekijken wat er in het model gebeurt als je een zin vertaalt en hoe deze zin wordt weergegeven in machinetaal.
Machinevertaling
1. Modelinvoer. Stel dat je een zin wilt vertalen van het Engels naar het Nederlands. De zin wordt als een reeks woorden in het model ingevoerd.
2. Codering. Er zijn meerdere manieren om een zin in machinetaal weer te geven. Een van deze methodes wordt one-hot codering genoemd. Voor one-hot codering hebben we een woordenschat nodig (voor de Engelse taal zijn dit ongeveer 170.000 woorden!) waarbij elk woord wordt gekoppeld aan een uniek ID.
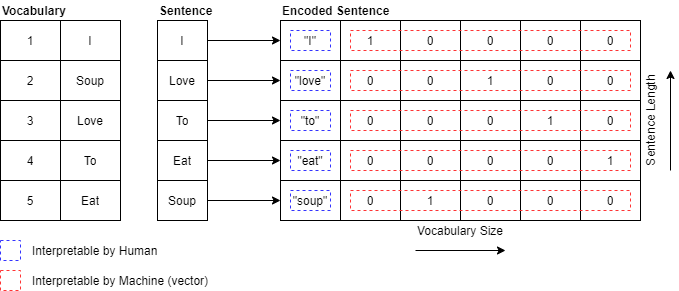
3. Terugkerende lagen. De zin wordt woord voor woord verwerkt. De context van het vorige woord in de reeks wordt toegepast op het woord dat momenteel wordt verwerkt. Dit gebeurt via de eerder genoemde 'lus'.
4. Decoder. De verwerkte zin wordt gedecodeerd tot een correcte vertaalde reeks.
5. Output. De vertaalde sequentie is een sequentie van één-hot-gecodeerde vectoren, en deze wordt in kaart gebracht naar een Nederlandse zin met behulp van de Nederlandse woordenschatdataset.
Hoewel het LSTM een grote verbetering is ten opzichte van eerdere technieken die geen gebruik konden maken van deze 'geheugen'-eigenschap, schiet het nog steeds tekort op het gebied van 'aandacht'. De LSTM heeft nog steeds een relatief kort geheugen. Als je bijvoorbeeld langere zinnen gebruikt om te vertalen (langere reeksen), verliest het model nog steeds aandacht voor eerder voorkomende woorden die relevant zouden kunnen zijn in de context. Gelukkig zijn er al veelbelovende oplossingen voor dit probleem, die we zeker zullen behandelen in een vervolgartikel. Kijk ernaar uit!

