

Although Mark Rutte seems to have spilled these facts about AI Heroes being the hottest start-up in Amsterdam, he has not actually said this during his speech. This video was created using Artificial Intelligence (AI). It was made using a combination of real footage of our prime minister during his speech and an audio fragment of the desired message we want him to say. Since Mark Rutte did not really say these words, we use AI to move his lips so that the audio fragment aligns with the video footage. Let’s dive deeper into the techniques behind how these so-called face-reenactments (also known as ‘deepfakes’) are created.
The intuition of the technique
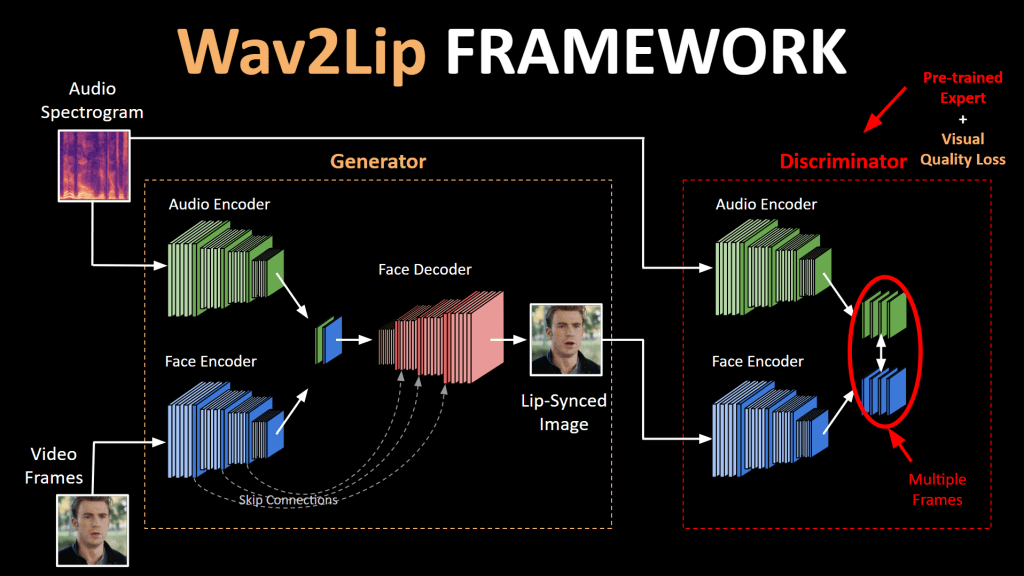
Syncing the lips of the person talking to the audio fragment is actually done using quite intuitive techniques. The video in this blog was made using a model called Wav2Lip, and the creators describe their model as “Generating accurate lip-sync by learning from a well-trained lip sync expert”[1]. This is what essentially describes how a General Adversarial Neural Network (GAN) works, which is the classic model used to make these face-reenactment videos.
GAN’s were initially developed for image generation but adapted to enable video generation. The important difference between image and video generation is that for video generation, temporal consistency matters. This means that the frames that are individually generated, need to be in line with other frames to resemble a ‘movement’ over time.
Technology
A GAN uses two neural networks that essentially communicate with each other to become a better version of themselves. Like two chess players becoming better when they play against each other. This trains the GAN to generate lifelike lip-syncs.
The first neural network (the ‘generator’) generates an image from the face pose in the original video merged with the lower half of the face which was generated (the synced lips). The corresponding audio segment is also given as input to the generator and the network generates the input face crop, but with the mouth region morphed.
The second network is the so-called ‘discriminator’. The discriminator is trained to discriminate ‘sync’ between audio and video by randomly sampling an audio fragment that is either in-sync with the video or from a different time-step (out-of-sync). This is what we called the ‘lip-sync expert’ in the beginning, and will be used to judge if the generator is generating lifelike lip-syncs or not. The model uses this judgment from the discriminator to improve and generate more accurate lip-syncs each iteration! Once our lips-sync expert cannot distinguish the real video and the generated video from each other, the model is properly trained, and we can use it to create realistic-looking face-reenactments.
Adaptations
The technology of face-reenactments has enabled us to artificially create videos that are extremely lifelike. Because of this, some people are worried it might contribute to for example the spread of fake-news and revenge videos. While this may be true, there are also a lot of ways in which we can use deepfakes for a good cause. For example, translations of speeches can be synced to match the lips of the speaker to the language it was translated to. Also, dubbed tv-shows can be lip-synced to match the dubbed language. Additionally, we can use these techniques to make the process of creating animation movies a lot more efficient and accurate by generating a character’s facial movement.
Besides these practical applications, the technique of creating lifelike face-reenactments is not as inaccessible as it may seem. Where Martin Scorsese spent millions of dollars to digitally de-age Robert De Niro using traditional CGI for the movie The Irishmen, a YouTuber attempted the same thing using free accessible AI-software. This only took him seven days and it looks a lot better! Read more about this.
The techniques of generating these deepfakes look promising and sometimes seems to work almost perfect already. However, there is still a lot to learn regarding ethical concerns and how to apply these techniques in ways where it can be really useful. Whether that might be to break language barriers, optimizing work processes, or creating silly videos, the future is here and AI Heroes is part of it!
Sources
- Prajwal, K. R., et al. “A Lip Sync Expert Is All You Need for Speech to Lip Generation In the Wild.” Proceedings of the 28th ACM International Conference on Multimedia, ACM, 2020, pp. 484–92. DOI.org (Crossref), doi:10.1145/3394171.3413532.
- Matt Miller, “Some Deepfaker on YouTube Spent Seven Days Fixing the Shitty De-Aging in The Irishman”, Jan 2020.


