Chinese machine translation systems: way ahead of us or simply a bad translation?
A fundamental part of being human is the ability to communicate with each other. With roughly 6500 languages spoken worldwide, and our world becoming more and more connected through advancing technologies and fast globalisation, machine language translation is an essential part of our existence. Fast and accurate language translations largely serve as our bridge between people from other countries and ethnic communities.
To actually provide these fast and accurate translations, various companies have largely invested in machine translation over the last few years. Also, many advancements in the field of Artificial Intelligence have been made. Specifically in the field of deep learning: a subfield within AI concerning algorithms inspired by the structure and function of the brain called ‘Artificial Neural Networks’. Together with these investments, AI has enabled a significant improvement on the quality of machine translations. Google stated a few years ago that “switching to deep learning produced a 60% increase in translation accuracy”[1]. But how does machine translation (specifically, Google Translate) work and what enables it to perform so well?
Google Translations
Previously, Google used a statistical machine translation (SMT) method, which required the input text to be converted to English before it could be translated to the desired language. This takes extra time and since SMT used predictive algorithms to translate the text, there was also more room for poor grammatical translations.
Nowadays the Google Neural Machine Translation system (GNMT) uses a Long Short-Term Memory Neural Network (LSTM) for their machine translations. The GNMT works so efficiently, because it shares its parameters between language pairs to train itself. When someone translates a sentence from Japanese to English and from Spanish to English, the model learns these translations and is able to adapt this knowledge when someone wants to translate a contextually similar sentence from Japanese to Spanish (which can be a language pair that the model has never seen before in the context of the provided sentence!). This is called “zero-shot” translation.
Also, GNMT translates whole sentences at once, rather than word by word or even character by character. It makes use of a broader context to figure out the most relevant translation, which is then rearranged and tweaked to resemble more human-like spoken language with properly used grammar.
LSTMS
Why do these so-called LSTM’s work so well? In a traditional (‘fully-connected’) neural network model, information flows one-way only: from input to output and is only able to process single data points at a time. It ‘forgets’ the information of the data that it has already processed, whereas our biological brain is able to maintain such information in our long or short-term memory.
A LSTM is a type of Recurrent Neural Network (RNN). As opposed to traditional neural networks, RNN’s take sequences of data as an input and also return sequences of data as the output. For machine translation this data sequence is a piece of text, but this can also be an audio fragment or sequence of stock prices. The important matter is that the data is sequential. A RNN is ‘recurrent’, because each layer in the model has a loop that uses information found earlier in the model. This loop enables relevant outputs from previous timesteps to be used and applied to the model learning at the current time step. What differs the LSTM from a RNN is that a LSTM is able to filter ‘relevant’ and ‘irrelevant’ information in each of these loops. This recurrence serves as the ‘memory’ of the model.
Let’s globally go through what happens inside the model when you translate a sentence, and how this sentence is represented in machine language.
Machine Translation
1. Model inputs. Say that you want to translate a sentence from English to Dutch. The sentence is fed as a sequence of words into the model.
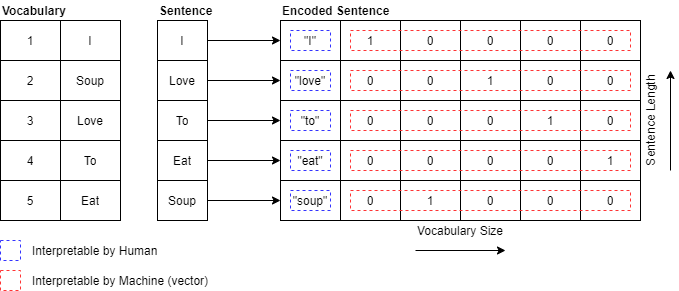
2. Encoding. There are multiple ways to represent a sentence in machine language. One of these methods is called one-hot encoding. For one-hot encoding we need a vocabulary of words (for the English language this is about 170.000 words!) where each word is mapped to a unique ID.
3. Recurrent layers. The sentence is processed word by word. The context of the previous word in the sequence is applied to the word currently processed. This is done through the ‘loop’ mentioned earlier.
4. Decoder. The processed sentence is decoded to a correct translated sequence.
5. Output. The translated sequence is a sequence of one-hot encoded vectors, and this is mapped to a Dutch sentence using the Dutch vocabulary dataset.
While the LSTM is a great improvement compared to earlier techniques which could not make use of this ‘memory’ feature, it still falls short in terms of ‘attention’. The LSTM still has a relatively short memory. If you use longer sentences to translate for example (longer sequences), the model still loses attention to previously occurred words that could be relevant in the context. Luckily there are already promising solutions to this problem which we’ll definitely cover in a follow-up article. Look forward to it!